简介
在这一章, 我们将会去探索 CUDA 中组成 Falsh Attention 核的基础操作.Flash Attention 的性能取决于两点:其一,通过 Tensor Core 充分提升计算吞吐;其二,通过高效的数据搬运降低内存瓶颈。
为了说明这些因素为何关键,先来看一个典型 attention 切片的算术复杂度:设有 64 个 query 向量,关注 4096 个 key-value 向量,且 $d_{\text{head}}=128$。对应的 attention 计算为:
\[\mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d_{\text{head}}}}\right)V\]在该设定下,计算量约为 $135.8\text{M}$ 次浮点运算,而从 GMEM 读取/写回的数据仅约 $2.1\text{M}$ 字节。由此可得算术强度(arithmetic intensity)约为 $64$,即每从内存加载 1 字节数据,平均可执行约 64 次数学运算。
这种较高的算术强度,使 Flash Attention 成为 Tensor Core 的理想负载。与常规浮点运算单元相比,这类专用计算单元能够提供明显更高的吞吐能力;但其峰值性能通常建立在“计算远超于访存”的前提之上。当前约 $64:1$ 的计算/访存比意味着:Tensor Core 可以持续执行矩阵运算,而数据搬运则在后台并行进行,从而最大化硬件利用率。
接下来我们将分三个阶段构建这套指令工具箱;在每个阶段中,都优先采用 Ampere 架构上性能最优的指令:
- 高吞吐矩阵运算:使用 Tensor Core 的
mma(matrix multiply-accumulate)指令。 - 高效内存操作:使用能够持续维持高带宽利用率的数据搬运原语(汇编原子指令)。
- 配套支撑操作:包括数据类型转换及其他关键实现细节。
矩阵乘法
Flash Attention 的性能本质上取决于两次矩阵乘法,因此我们首先讨论如何利用 Ampere 架构的 Tensor Core 来加速这两类计算。在内核实现中,输入与输出张量采用 bf16/fp16 精度,而 softmax 的计算则使用 fp32,以保证数值稳定性。
Ampere 架构上的 Tensor Core 以 fragment 为基本操作对象。可以将其理解为存放在线程寄存器中的矩阵 tile。
Fragment 定义
在本系列中,术语 fragment 特指跨一个 warp 存储于寄存器文件中的一个 $(8,8)$ tile。
其中,warp 内每个线程仅持有 2 个元素,但整个 warp 协同完成乘法计算。
这就是 Tensor Core 运算的基本单元。
一个 warp 里面有 32 个线程, 而每个线程自己独占的寄存器里面存放 2 个元素, 总共就是 64个元素, 对应上述所说的$(8,8)$ tile.
mma 指令
那么,如何在实现层面真正驱动 Tensor Core 呢?关键就在于 mma(matrix multiply-accumulate)这条 PTX 指令。
需要说明的是,编程 Tensor Core 还有另一类指令接口:wmma。但在本文中我们选择 mma,主要原因是其 fragment 布局对开发者更透明,便于精细控制数据映射与指令行为。若你想进一步了解这一取舍背后的思考,可参考 wmma API。
PTX / mma / wmma 关系速览
PTX 是 CUDA 的中间层汇编(虚拟 ISA)。CUDA C++ 代码通常先编译为 PTX,再由驱动/JIT 转为目标 GPU 的机器码。
mma 是 PTX 层的低层 Tensor Core 矩阵乘加指令;wmma 是 CUDA 提供的高层 Warp Matrix API,底层通常映射到 mma/相关 Tensor Core 指令。mma 和 wmma, 以我的理解,类似于 cpu 中 asm 和 intrinsic 的关系;
三层关系:
- CUDA C++(高层)
- wmma API(高层封装)
- PTX mma(低层指令)→ GPU 机器码(最终执行)
实践取舍:wmma 开发更快;mma 控制更细、调优空间更大,适合 FlashAttention 这类极致性能内核。
mma 指令执行的运算形式为:
其中:
- $A$ 的形状为 $(m, k)$
- $B$ 的形状为 $(n, k)$
- $C$ 与 $D$ 的形状均为 $(m, n)$,并且两者可以指向同一块内存地址
需要注意的是,尽管我们在内存中以行主序(row-major)存储 $B$(即同一行元素在内存中相邻),mma 实际参与乘法的是 $B^\top$。在将 attention 张量映射到这些操作数时,这一点尤为关键。
对于本文使用的具体 mma 指令,其操作数的形状与数据类型由指令规格决定,维度为 $(m=16,\ n=8,\ k=16)$。在 Ampere 架构上,针对 16-bit 输入、32-bit 累加的候选指令有两种:m16n8k8 与 m16n8k16。综合效率考虑,本文选择 m16n8k16。
表 1:m16n8k16 指令下各操作数的形状与寄存器映射
| Operand | DType | Shape (Variables) | Shape (Elements) | Shape (Fragments) | Shape (Registers) |
|---|---|---|---|---|---|
| A | BF16/FP16 | $(m, k)$ | $(16, 16)$ | $(2, 2)$ | $(2, 2)$ |
| B | BF16/FP16 | $(n, k)$ | $(8, 16)$ | $(1, 2)$ | $(1, 2)$ |
| C/D | FP32 | $(m, n)$ | $(16, 8)$ | $(2, 1)$ | $(2, 2)$ |
解释一下这个表; Elements 和 Fragments 都比较好理解, Fragments 就是 Elements Shape 除以 8x8 得到的;
Registers 则是按照每个线程视角来看, 每 8x8 tile, 一个线程私有寄存器里面有两个 elements, 对 BF16 这种 16bit 的数据而言, 寄存器单位是 uint32_t, 所以一个寄存器单位可以存两个元素, 对于 (16,16) 其实是 持有 8 个元素, 分别存在 (2,2) uint32_t 的寄存器槽位中, B 同理;
对于 C 而言, 因为 m16n8k16 是一个 warp 级别指令, 计算完整个矩阵操作后, 得到 (16,8) 个元素的矩阵,分到每个线程头上就是 16x8/32 = 4, 每个线程持有 4个 32bit 的值,所以对应寄存器槽位是 (2,2);
Attention Tensors 如何映射到 mma 指令上呢?
在明确 mma 指令的操作数定义之后,下面讨论 Flash Attention 中各张量如何映射到这些操作数。该映射至关重要,因为它直接决定了整个 kernel 中数据的存储组织与访问方式。
Flash Attention 包含两次核心矩阵乘法:
- $\mathbf{QK}^\top$:计算 query 与 key 之间的注意力分数
- $\tilde{\mathbf{P}}\mathbf{V}$:将注意力权重作用于 value
由于第一步存在转置操作,同时两步对内存布局效率的要求不同,这两次乘法对应的“张量到操作数”映射也不相同。
下面给出相应的存储布局。
| Tensor | Operand | Storage Format in SMEM & GMEM | SMEM Tile Shape | Storage Format in RF | Effective Shape in RF (not actual storage) |
|---|---|---|---|---|---|
| $\mathbf{Q}$ | A | row-major | $(B_r, d_{\text{head}})$ | row-major | $(B_r, d_{\text{head}})$ |
| $\mathbf{K}^{(j)}$ | B | row-major | $(B_c, d_{\text{head}})$ | row-major | $(B_c, d_{\text{head}})$ |
| $\tilde{\mathbf{P}}$ | A | N/A | N/A | row-major | $(B_r, B_c)$ |
| $\mathbf{V}^{(j)}$ | B | row-major | $(B_c, d_{\text{head}})$ | col-major* | $(d_{\text{head}}, B_c)$ |
注: 首先就要理解,上述这张表其实是 block level(CTA level) 处理的数据;
这张表刚看会令人很费解, 不知道这是在做什么,突然又冒出来这么多参数; 在这里我来简要解释一下 flash Attention 怎么将大矩阵的乘法,分散到每一个 warp 中去做;
输入数据 shape(Q,K,V): (batch_size = 16, seq_len=4096, n_heads = 16, d_head = 128)
def generate_qkv(cfg: QKVConfig):
q = torch.randn(
(cfg.batch_size, cfg.seq_len, cfg.n_heads, cfg.d_head),
dtype=cfg.dtype,
device=cfg.device,
)
k = torch.randn_like(q)
v = torch.randn_like(q)
return q, k, v
然后固定 batch 和 n_heads 维度, d_head 是每个 head 的维度, 所以 (seq_len, d_head) 就需要被分成小矩阵块去做 attention 的过程, 然后就是 $B_r$ 和 $B_c$ 就是按照 seq_len 这个维度来切割, 以决定每个 Block 处理多大的 $Q$,$K$,$V$ 块, 为了更好理解核函数的实现,暂定 $B_r = 64, B_c=64$. 更细致的后面会讲到;
✎ 为什么 V 在 RF 中需要列主序存储
`mma` 指令执行的是 $AB^\top + C$,而我们目标计算的是 $\tilde{\mathbf{P}}\mathbf{V}$(不带显式转置)。为使两者一致,可采用如下映射策略:
- 在 GMEM 与 SMEM 中,$\mathbf{V}$ 保持常规行主序(row-major)存储;
- 加载到 RF 时,对其做一次逻辑转置,使其在寄存器视角下等效为 $\mathbf{V}^\top$;
- 这样 `mma` 实际计算 $\tilde{\mathbf{P}}(\mathbf{V}^\top)^\top=\tilde{\mathbf{P}}\mathbf{V}$,结果与目标表达式一致。
例如,若 $\mathbf{V}$ 在 GMEM/SMEM 中形状为 $(64,128)$,则在 RF 中按转置视角组织为等效 $(128,64)$,从而无需在计算路径中额外插入一次显式 transpose,即可得到正确输出。
该转置通常通过 `ldmatrix` 的 transpose 变体完成,后续章节将详细展开(ldmatrix Transpose)。
Fragment 存储和分布
这里有一个必须先明确的关键点:Tensor Core 相关运算并非由单个线程独立完成,而是以 warp 为执行单位协同进行。整个 warp 会以 lockstep 方式执行同一条指令,即所有线程必须同步发射并共同等待该指令完成。
由于一个 fragment 的不同元素分散存放在 warp 内各线程的寄存器中,我们需要进一步理解:在一个 warp 内,fragment 究竟是如何在线程之间分布与映射的。
Fragment 在线程间寄存器中的布局方式
理解 fragment 的线程分布,是实现高效内存访问模式的关键。核心结论是:一个 warp 会划分为 8 个线程组,每组 4 个线程 协同处理一个 $(8,8)$ fragment。
# mma fragment 存储时,线程 ID 到 (row, column) 的映射
row = (tid % 32) / 4
col = (tid % 4) * 2在线程映射上,线程 0–3 共同负责第一行:其中线程 0 存储元素 0 和 1,线程 1 存储元素 2 和 3,其余线程以同样规律依次分配。下方示意图将直观展示这一布局方式。


在每一行中,我们会对应多个 fragment。

注: 这里怎么理解?
图1 和 图2 其实就是说一个 warp 内, 每一个线程拿了 8x8 fragment 里面的哪两个元素;
图 3 的意思是说, 我 T0 线程, 有一个寄存器数组 uint32_t rf[2][16];
其中 rf[0][0] 拿了 fragment 0 的两个元素, rf[0][1] 则拿了 fragment 1 的两个元素, fragment 0 和 fragment 1 是两个不同的 8x8 fragment;
不同类型的操作矩阵在线程寄存器中的存储方式
A 和 B 操作矩阵
对于 fragment A 和 B,warp 内每个线程都会在一个 32-bit 寄存器中存放 2 个元素。由于这两类操作数通常不需要被直接修改,我们可以将其打包存为单个 uint32_t。
为便于描述,这里构造一个二维数组 $M$,并令 $M_{i,j}=M[i][j]$,其中 $i,j$ 表示 fragment 的索引:
- $0 \le i < \text{rows}/8$
- $0 \le j < \text{cols}/8$
uint32_t input[rows/8][cols/8]; // each register represents one (8x8) fragment unit
这里就是单个线程的寄存器空间, 对于 $(16,128)$ 的 Tensor 而言, input[2][16] 就存储了 32 个 fragment 的元素碎片, 这个元素碎片大小就是 2 个 BF16, 占据一个 uint32_t 槽位;
✎ Array Storage
这里使用二维数组主要是为了表达更直观;在生产代码中,更推荐使用一维数组,并结合编译期 stride 计算来组织索引与访存。
C 和 D 操作矩阵
对于 C 与 D 操作数,每个 fragment 需要存放 2 个 float 值。我们构造二维数组时,会让同一 fragment 的这两个值在内存中相邻排列:
float accum[m/8][n/4]; // each pair of registers represents one (8x8) fragment unit
以 $(16,64)$ 的输出为例,每个线程存放 (2,8) fragment 的元素碎片, 总计 (2,8) x2 = 32 的元素碎片,且同一个 fragment 的 2 个元素碎片在寄存器中地址需连续, accum[2][16] 需要 32 个 float 槽位; (这里原文写成 64 个 registers 就很让人费解,所以按照我的讲述来就可以了).
从逻辑视角看,对应的 mma 运算可写为:

由于我们将矩阵 B 以行主序(row-major)格式存储,因此上图中的 B1 与 B2 这两个 fragment 实际上是沿“行方向”提取的,而不是沿“列方向”提取。如下所示:

mma code 实现
下面给出该指令对应的 PTX 封装(wrapper)。这里不显式传入 D 操作数参数,因为我们的实现始终采用“累加到 C”的写回语义:
ptx_functions.cuh
template <typename value_t>
__device__ void
mma_m16n8k16_f32_accum(
float &d1, float &d2, float &d3, float &d4,
uint32_t const &a1, uint32_t const &a2,
uint32_t const &a3, uint32_t const &a4,
uint32_t const &b1, uint32_t const &b2,
float const &c1, float const &c2,
float const &c3, float const &c4
) {
static_assert(std::is_same_v<value_t, half> ||
std::is_same_v<value_t, nv_bfloat16>,
"value_t must be either half or nv_bfloat16");
if constexpr (std::is_same_v<value_t, nv_bfloat16>) {
asm volatile("mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32 "
" { %0, %1, %2, %3 }, "
" { %4, %5, %6, %7 }, "
" { %8, %9 }, "
" { %10, %11, %12, %13 }; "
: "=f"(d1), "=f"(d2), "=f"(d3), "=f"(d4)
: "r"(a1), "r"(a2), "r"(a3), "r"(a4), "r"(b1), "r"(b2),
"f"(c1), "f"(c2), "f"(c3), "f"(c4));
} else {
// FP16 variant
asm volatile("mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
" { %0, %1, %2, %3 }, "
" { %4, %5, %6, %7 }, "
" { %8, %9 }, "
" { %10, %11, %12, %13 }; "
: "=f"(d1), "=f"(d2), "=f"(d3), "=f"(d4)
: "r"(a1), "r"(a2), "r"(a3), "r"(a4), "r"(b1), "r"(b2),
"f"(c1), "f"(c2), "f"(c3), "f"(c4));
}
}- 这同样是一条 warp 级别 指令。
a1, a2, a3, a4表示当前线程寄存器中的 8 个bf16值,对应于表达式 $AB^\top + C$ 中A矩阵的局部片段。b1, b2表示当前线程寄存器中的 4 个bf16值,对应于B矩阵的局部片段。- 对于
m16n8k16这一指令形状:A的维度为16x16,B的维度为8x16,C的维度为16x8(C的数据类型为float)。 - Tensor Core 完成该子块的矩阵乘加后,输出结果为
16x8的float矩阵。该结果按 warp 内 32 个线程分摊:16x8 / 32 = 4,因此每个线程寄存器持有 4 个C(或累加结果)矩阵元素。
矩阵计算小结
至此,我们已经说明了如何基于 Tensor Core 的 mma 指令实现高吞吐矩阵乘法。核心结论是:FlashAttention 中的两次矩阵运算($QK^\top$ 与 $\tilde{P}V$)都可以自然映射到 mma 的操作数定义上;其中 $V^{(j)}$ 需要在数据布局/加载阶段进行转置处理,以保证计算语义正确。
在矩阵乘法路径明确之后,下一步将转向另一个更具挑战的问题:如何高效完成整条计算链路中的数据搬运与访存组织。
内存传输操作
在明确了 Tensor Core 执行矩阵乘法的机制之后,下面转向另一个同样关键的问题:如何在不同存储层级之间高效搬运数据,以持续为计算单元提供数据、避免因访存瓶颈导致吞吐下降。
在展开具体的数据传输操作之前,先回顾一下本文后续将涉及的 GPU 存储层级结构。其实也是 Nvidia GPU 的通用架构;
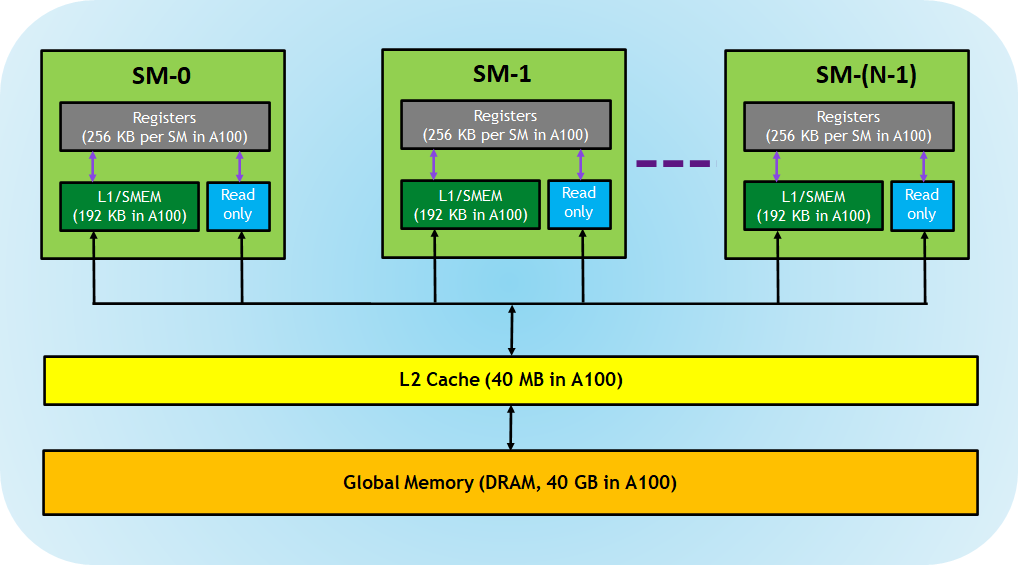
关于内存层级,我还有更多的想说; 寄存器是每个线程私有的, 而 SMEM 共享内存则是每个 CTA/Block 共享的; 每个 SM 都有自己的一块 shared memory, 而每个 block 则可以动态或静态的申请 SMEM, 但是每个 block 之间的 SMEM 是不能互相访问的;
数据搬运路径相对清晰:输入张量(Q、K、V)沿 GMEM -> SMEM -> RF 方向流动并参与计算;输出张量(O)则沿 RF -> SMEM -> GMEM 方向回写。为最大化整体吞吐,流水线中的每个阶段通常采用不同的专用指令实现。
GMEM → SMEM: cp.async 线程 level 指令
Ampere 架构为从 GMEM -> SMEM 的异步加载提供了硬件加速支持。在 PTX 层面,这类拷贝主要由以下指令组成:
cp.async:发起一次异步拷贝。- 单次拷贝大小可为
4、8或16字节,与常规 load 类似。 - 当拷贝大小为
16字节时,可选择让传输完全绕过 L1 cache,从而减少缓存污染,并提供一条从L2到共享内存的更直接路径。 - 本文将采用
16字节拷贝。
意思是,每个参与这条 cp.async 的线程,一次搬运 16 bytes 的数据。这就是线程级别的指令;
- 单次拷贝大小可为
-
cp.async.commit:将当前所有尚未提交的cp.async合并为一个 group,后续可将该 group 作为单一实体进行等待。 cp.async.wait_group n/cp.async.wait_all:等待最新的n个 group 之前的所有提交组完成。- 例如,当有 3 个 group 在 flight 时,
cp.async.wait_group 1会等待到仅剩 1 个 group 在 flight(即已有 2 个完成)。 cp.async.wait()只保证当前线程的加载完成;若线程之间通过共享内存通信,仍需配合合适作用域的同步屏障以保证正确同步(__syncwarp()/__syncthreads()/cooperative_group.sync())。
- 例如,当有 3 个 group 在 flight 时,
若想更深入对比与传统 load 的差异,可参考:cp.async vs Traditional Loads。
code
PTX 指令的包裹函数:
ptx_functions.cuh
__device__ void cp_async_commit() { asm volatile("cp.async.commit_group;"); }
template <int ngroups>
__device__ void cp_async_wait() {
asm volatile("cp.async.wait_group %0;" ::"n"(ngroups));
}
template <int size, typename T>
__device__ void cp_async(T *smem_to, T *gmem_from) {
static_assert(size == 16);
uint32_t smem_ptr = __cvta_generic_to_shared(smem_to);
// The .cg (cache-global) option bypasses the L1 cache, reducing cache
// pollution and providing a more direct path from L2 to shared memory.
asm volatile("cp.async.cg.shared.global [%0], [%1], %2;"
:
: "r"(smem_ptr), "l"(gmem_from), "n"(size));
}调用 __cvta_generic_to_shared() 的作用,是将通用 64-bit 地址空间中的指针转换为共享内存(SMEM)专用的 32-bit 地址表示;这种地址形式更贴近硬件寻址路径,通常具有更好的执行效率。
✎ LD/ST 操作
Tensors: $Q$, $K^{(j)}$, $V^{(j)}$
Transfer: 使用 cp.async 执行 $GMEM \rightarrow SMEM$ 传输(每线程 16B,warp 级总计 $(4,128)$ bytes),这个往下的小节会更深层次解读;
SMEM → GMEM: Vectorized Stores
遗憾的是,在 Ampere 架构上并不存在与 cp.async(GMEM -> SMEM)对应的 SMEM -> GMEM 异步写回指令(即 st.async 不受支持)。因此,这里的最优替代方案是使用 16-byte 向量化 store。
实现要点很直接:
- 指针所指向的数据类型应为 16-byte 宽类型;
- 指针地址需满足 16-byte 对齐约束,即
addr % 16 == 0。
reinterpret_cast<uint4*>(GMEM[dst])[0] = reinterpret_cast<uint4*>(SMEM[src])[0];向量化访存还存在一些额外细节,这里先不展开;在后续进一步优化内存访问路径时,我们会回到这一部分并进行更细致的讨论。
✎ LD/ST 操作
Tensors: O
Transfer: 使用标准 store 执行 SMEM -> GMEM 传输(每线程 16B,warp 级总计 (4,64)); 每线程 16bytes -> 128bit-> 8 个 BF16, 对应 32x8 = (4,64) BF16. 后续再看怎么对应上(4,64);
从 warp level 来看数据搬运 GMEM ↔ SMEM
在 warp 级数据传输中,为获得最优性能,需要尽可能保证内存访问合并(memory coalescing)。由于 GPU cache line 为 128B,且每个线程单次传输 16B,因此将 8 个线程映射到同一行时,恰好可以覆盖整条 cache line。由此可得:在每个 warp 含 32 个线程的前提下,一条 warp 级传输指令可搬运一个 (4,64) 的内存 tile。
下面给出一个 warp 在单次迭代中覆盖的数据范围示意。

这里就很明了了,单个线程一次搬 16B(8x Bf16), 为了满足 GPU 的合并内存访问(一次搬运 128B, 合并内存访问的概念就是对于连续地址内存,且地址对齐,一次搬 128B 只需要一次内存事务就可以实现 GMEM->SMEM 的搬运), 所以每 8 个线程去搬一行数据( 128B/16B = 8), 因为同一行的数据地址才是连续的, 一行 128B 就是 64个 Bf16 数据, 所以一个 warp 搬运 (4,64) tile 的数据;
在一个 warp 内,线程到坐标偏移(coordinate offset)的映射关系为:
row = (tid % 32) / 8;
col = tid % 8;数据 SMEM->RF
为了将 fragment 从 SMEM 搬运到 RF,一种直接做法是让每个线程逐个读取其负责存储的元素。该方案在功能上可行,但对每个 fragment 往往需要发射多条指令,效率并不理想。
更高效的方式是使用 ldmatrix 指令:它单次最多可加载 4 个 fragment。相较于手工执行 RF[dst] = SMEM[src] 的加载方式,ldmatrix 通常具有更高吞吐,但其数据布局与手工加载并不相同。尤其在需要同时完成转置(transpose)时,ldmatrix 的优势会更加明显。
ldmatrix
ldmatrix 可在一条指令中加载 1、2 或 4 个 (8,8) 矩阵 fragment。每个 fragment 由 8 个线程协同处理:线程 0-7 负责第 1 个 fragment,线程 8-15 负责第 2 个,以此类推。下表给出对应关系:
| Fragment | Threads |
|---|---|
| 1 | 0-7 |
| 2 | 8-15 |
| 3 | 16-23 |
| 4 | 24-31 |
在每个 8 线程小组(octet)内部,各线程会传入其在 SMEM 中对应行的指针;这些指针值随后会在整个 warp 范围内进行广播使用。

让我来解释一下这个图; 意思是每 8 个线程一组, 去做 SMEM 8x8 到 RF 8x8;
这张图的左侧就是, T0-T7 提供 8 个 SMEM 行地址, 每行对应 8 个元素, 然后对应的 SMEM 元素就被这个指令送到了 RF 中; (8x8 tile)
那根据 2.3 节所说的, 每 8x8 tile, 每个线程只持有 2 个元素, 所以 SMEM 中的 8 个元素就到了 32 个线程的 RF 寄存器中;也就是图 8 的右侧所示;
后续 T8-T15 提供另外一个 8x8 tile 的 8 个行地址, 去加载到对应 T0-T31 线程的 RF 寄存器中;
如果还不懂, 请关注以下 ldMatrix 怎么传参数;
加载哪一个 8x8 fragment 呢?
ldmatrix.x4 允许我们在一条指令中加载任意 4 个 (8,8) fragment。这意味着既可以加载连续的 (8,32) 或 (32,8) tile,也可以加载一组随机的非连续 fragment。(这里其实通过上一节就可以看出来,因为每 8 个线程都可以传不同的 SMEM 行地址)不同选择会影响最终生成的汇编形式。该问题将在 kernel 9 中进一步展开;而在当前阶段,我们采用更标准的配置:每条指令传输连续元素构成的 (16,16) tile,即对应 (2,2) 个 fragment tile。该布局在大多数场景下也是更优选择。

每 8 个线程负责一个 SMEM 中的 8x8 fragment, 如左图,非常明了;因为要加载 (16x16) 的 SMEM 数据到 RF 中, 布局就是这么布局;
ldmatrix 的寻址模式与 mma 的 fragment 布局并不相同,其核心原因在于:ldmatrix 的映射方式是围绕共享内存(SMEM)的高效访问模式进行优化的。对于 ldmatrix 操作,warp 内线程到 SMEM 地址偏移的映射关系如下:
// ldmatrix addressing (for loading from SMEM -> RF)
row = tid % 16;
col = ((tid % 32) / 16) * 8;下面给出我们对该 PTX 函数的封装(wrapper)。同时,我们将线程持有的 fragment 值以 uint32_t 形式传入:
ptx_functions.cuh
template <typename T>
__device__ void ldmatrix_x4(
T *load_from,
uint32_t &a1,
uint32_t &a2,
uint32_t &a3,
uint32_t &a4
) {
uint32_t smem_ptr = __cvta_generic_to_shared(load_from);
asm volatile("ldmatrix.sync.aligned.x4.m8n8.shared.b16"
"{%0, %1, %2, %3}, [%4];"
: "=r"(a1), "=r"(a2), "=r"(a3), "=r"(a4)
: "r"(smem_ptr));
}
ldmatrix_x4 虽然是一个 warp 级别的指令, 但是调用的时候, 其传入的参数和单个线程的职责相关; 上面说了, T0-T7 提供 SMEM 的 8 个行地址, 那么对应到单个线程, 这里传进去的参数 smem_ptr 则是当前线程 T0 负责传进去的那个行地址, 那 a1, a2, a3, a4 是什么, 上面也说了, 每个 8x8 fragment, 当前线程寄存器都持有 2 个元素, 所以 uint32_t a1, a2, a3, a4 就代表了放这 4 个 8x8 fragment 元素的寄存器;
SMEM->RF 是以 16x16 为单位, 后面矩阵运算 m16n8k16, 再去遍历寄存器, 所以矩阵乘法怎么运算和这里加载是独立分开来看的.
ldmatrix Transpose 转置
ldmatrix 指令提供了一个转置(transpose)变体,其行为与普通 ldmatrix 基本一致,区别在于:每个 fragment 在加载后会执行转置。该转置仅发生在 fragment 内部,不会在不同 fragment 之间进行重排。换言之,每个线程最终持有的是对应 fragment 转置后的数据元素。

在计算 $P^{(j)}V^{(j)}$ 时,我们使用 ldmatrix 的转置变体来加载 $V^{(j)}$ 的各个 fragment。
对应的转置版本封装与普通版本几乎一致:
template <typename T>
__device__ void ldmatrix_x4_transpose(
T *load_from,
uint32_t &a1,
uint32_t &a2,
uint32_t &a3,
uint32_t &a4
) {
uint32_t smem_ptr = __cvta_generic_to_shared(load_from);
asm volatile("ldmatrix.sync.aligned.x4.trans.m8n8.shared.b16"
"{%0, %1, %2, %3}, [%4];"
: "=r"(a1), "=r"(a2), "=r"(a3), "=r"(a4)
: "r"(smem_ptr));
}
这个函数传参数类似于正常版本,只是 8x8 fragment 里面的元素发生了转置, 每个线程持有的元素碎片发生了变化;
为满足 $V^{(j)}$ 的转置需求,我们需要做两处调整:
- 调用
ldmatrix的转置变体,使每个 $(8,8)$ fragment 内部完成转置; - 交换
a2与a3两个参数,以在 $(2,2)$ 的 fragment tile 内实现 fragment 之间的转置。
这两步结合后,等价于将整个 $(16,16)$ tile 转置为我们所需的列主序布局,从而用于 $\tilde{P}V^{(j)}$ 的计算。其必要性在于:mma 实际执行的是 $AB^{\top}+C$,而我们的目标是计算 $\tilde{P}V^{(j)}$(不带转置)。因此,将寄存器中的 $V^{(j)}$ 按“等效 $V^{(j)\top}$”的形式组织后,mma 指令即可得到目标结果。

ldmatrix.x4.trans 将数据从 SMEM 载入 RF,单条指令处理一个 $(16,16)$ tile,即 $(2,2)$ 个 fragment。
数据 RF → SMEM
存在一条与 ldmatrix 功能相近的指令 stmatrix,可将 fragment 从 RF 写回到 SMEM。遗憾的是,该指令仅在 Hopper 及之后的架构上可用,因此这里仍采用常规的 4B 标量写回方式,即 SMEM[i] = RF[i];。
线程到地址的映射将遵循 mma 的布局格式:
- 在单个 fragment 内,共有 $8$ 行,每行对应 $4$ 个线程;
- 每个线程写回 $2$ 个数值(共 $4\text{B}$);
- 因此,单条指令可完成一个 fragment 的存储。

Memory Operations Summary
至此,我们已经建立了贯穿整个存储层级的高效数据通路:cp.async 用于异步的 GMEM$\to$SMEM 传输,ldmatrix 用于优化的 SMEM$\to$RF 加载(并支持对 $V^{(j)}$ 的转置需求),回传路径则分别采用标准 4B 与 16B store,对应 RF$\to$SMEM 与 SMEM$\to$GMEM。
数据类型转换
我们已经介绍了核心矩阵计算与内存传输流程,但还剩下最后一块关键拼图:数据类型转换。
mma 指令输出的是 FP32 结果,而在后续流程中,我们需要在两个关键位置将其转换为 16-bit 精度:
Softmax 输出转换: 在完成注意力分数计算并执行 softmax(为保证数值稳定性,该过程在 FP32 中进行)后,需要将注意力矩阵 $\tilde{P}$ 转回 16-bit,以用于后续的 $\tilde{P}V$ 乘法。该转换在每次迭代中执行一次。
最终输出转换: 累积得到的输出向量在计算阶段保持 FP32 精度,但在写回全局内存之前,必须转换为 16-bit。
高效的成对转换
尽管 CUDA 提供了单值转换函数(例如 __float2bfloat16_rn() 与 __float2half_rn()),但在这里我们可以采用更高效的方式。由于 fragment 中的数值个数通常为偶数,我们可以一次完成两个数值的转换:
- BF16:
__float22bfloat162_rn()将float2转换为bfloat162; - FP16:
__float22half2_rn()将float2转换为half2。
这种“成对转换”更高效的原因在于,底层 SASS 指令本身主要面向成对转换设计。即便调用单值转换,编译后通常也会映射到成对版本,并将未使用的槽位以 0(zero) 填充。
总结
至此,我们已经覆盖了 Flash Attention kernel 的核心构建模块。简要总结如下:
整个计算流水线围绕 fragment 展开。fragment 是大小为 $(8,8)$ 的 tile,使 warp 内线程能够高效协作。每个线程在单个 fragment 中仅持有 $2$ 个元素,而 mma 指令负责在 warp 级别组织矩阵乘法,从而充分发挥 Tensor Core 的吞吐能力。
在 内存操作 方面,数据流形成了一套精细协同机制:cp.async 负责将数据从全局内存异步搬运至共享内存,ldmatrix 负责将 fragment 高效装载到寄存器,向量化 store 则将结果高效写回。整条路径都针对 Ampere 架构特性进行了优化。对应的 warp 级线程到 $(\text{row}, \text{col})$ 映射公式如下。
| Operation | Row | Column |
|---|---|---|
mma fragment / RF $\to$ SMEM |
$(\text{tid} \bmod 32) / 4$ | $(\text{tid} \bmod 4) * 2$ |
SMEM $\to$ RF (ldmatrix) |
$\text{tid} \bmod 16$ | $\left((\text{tid} \bmod 32) / 16\right) * 8$ |
| GMEM $\leftrightarrow$ SMEM | $(\text{tid} \bmod 32) / 8$ | $\text{tid} \bmod 8$ |
Warp 级操作的线程到坐标映射(Kernels 1-8)
mma 指令执行的计算形式为:$D = AB^{\top} + C$。下文将进一步给出我们所采用具体变体(m16n8k16)对应的操作数数据类型与张量形状。
| Operand | DType | Shape (Variables) | Shape (Elements) | Shape (Fragments) | Shape (Registers) |
|---|---|---|---|---|---|
| A | BF16/FP16 | $(m, k)$ | $(16, 16)$ | $(2, 2)$ | $(2, 2)$ |
| B | BF16/FP16 | $(n, k)$ | $(8, 16)$ | $(1, 2)$ | $(1, 2)$ |
| C + D | FP32 | $(m, n)$ | $(16, 8)$ | $(2, 1)$ | $(2, 2)$ |
MMA m16n8k16 指令的操作数形状定义
这个表的 registers 单位大小是 uint32_t, 原文里面在不同地方混淆 register 的单位大小, 看起来让人疑惑;
接下来将基于上述形状约束,说明我们在 kernel 中对应执行的 load/store 操作路径。
| From | To | Blocks | PTX Instr. / C++ | Warp-Wide Op Size | Thread Op Size | Thread ID Mapping Order | Register Shape | Notes |
|---|---|---|---|---|---|---|---|---|
| GMEM | SMEM | $Q$, $K^{(j)}$, $V^{(j)}$ | cp.async |
$(4, 64)$ | $(1, 8)$ | Row-major | ||
| SMEM | RF | $Q$, $K^{(j)}$, $V^{(j)}$ | ldmatrix.x4 |
$(16, 16)$ | $(1, 8)$ | Column-major | $(2, 2)$ | $V^{(j)}$ transpose |
| RF | SMEM | $O$ | standard (4B) | $(8, 8)$ | $(1, 2)$ | Row-major | $(1, 1)$ | |
| SMEM | GMEM | $O$ | standard (16B) | $(4, 64)$ | $(1, 8)$ | Row-major |
Load/store operation specifications across memory hierarchy
下一步
至此,我们已经具备了高性能 CUDA 操作所需的核心工具集,接下来可以将这些模块组装为一个可运行的 Flash Attention kernel。在下一部分中,我们将聚焦更具挑战性的实现环节:如何把这些构建块整合为完整实现。完成后,我们将得到一个可工作的 Flash Attention kernel,其性能预计可达到参考实现的约 $49\%$。