简介
在 Chapter3(Kernel 1)中,我们已经拿到了一个可运行的 baseline kernel,但性能仅约为参考实现的一半。
这一章的核心目标是定位瓶颈并解决它:bank conflicts。
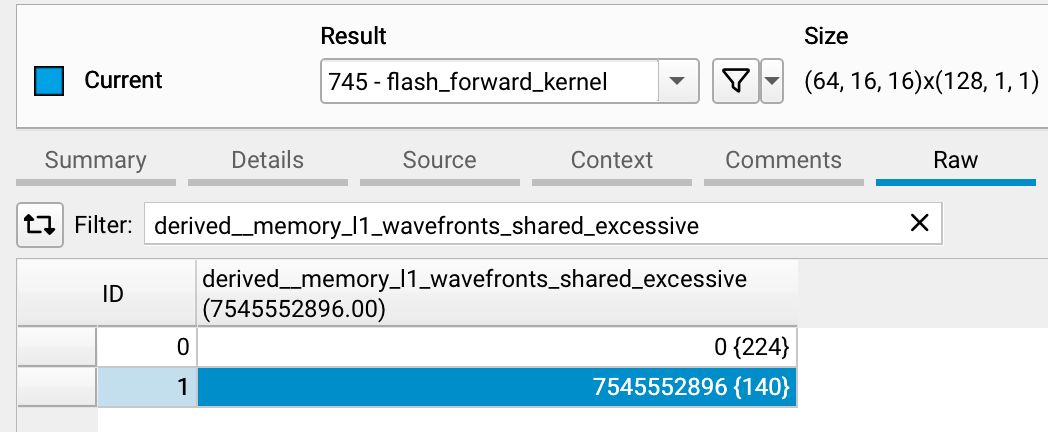
通过 Nsight Compute 分析可以看到,Kernel 1 在 SMEM 上存在严重冲突,导致大量访存串行化。
本章将引入并实现 swizzling,最终把性能从 33.28 TFLOPS 提升到 66.12 TFLOPS,接近参考实现。
Kernel 2:Swizzling
Kernel 1 的关键问题:
- SMEM 带宽利用率异常高(约
93.64%,远高于无冲突情况下的期望) short_scoreboard与mio_throttlestall 占比明显偏高- 根因是多处
8-waybank conflicts

16B 向量化访存下的 Bank 模型
对于 16B 的 LD/ST 指令,warp 的执行是分 phase 的:
| Phase | Threads |
|---|---|
| 0 | 0-7 |
| 1 | 8-15 |
| 2 | 16-23 |
| 3 | 24-31 |
可将其理解为:每个 phase 由 8 个线程组成,每线程访问 16B;因此有效地形成 8 个 16B banks(而非传统 32 个 4B banks)。
冲突判定原则:
- 同一 phase 内:若多个线程访问同一 bank 的不同地址,则产生 bank conflict
- 跨 phase:可访问同一 bank 而不互相冲突




Kernel 1 中的冲突位置
在本 kernel 中,冲突主要出现在两处:
- SMEM -> RF(
ldmatrix):同 phase 线程访问同一 bank,出现8-way冲突 - RF -> SMEM(4B store):线程映射导致每 4 间隔线程落同 bank,同样
8-way冲突
而 GMEM <-> SMEM 路径是无冲突的。



冲突带来的性能后果
bank conflict 会把本应并行的访存序列化,导致 wavefront 数显著增加。
在 Kernel 1 中,SMEM 路径几乎被冲突拖满。

典型 stall 指标(Kernel 1):
| Stall | % of All Stalls |
|---|---|
short_scoreboard |
56.37% |
math_pipe_throttle |
11.88% |
mio_throttle |
11.66% |
long_scoreboard |
6.31% |
Swizzling 思想
swizzling 的目标是:保持逻辑索引不变语义下,让访问分散到不同物理 bank,避免同 phase 冲突。
在 toy example(4x4)中,我们把原访问:
arr[row][col]
改为:
arr[row][row XOR col]
并且注意:写入 SMEM 与读取 SMEM 都必须使用同一 swizzled 映射,否则数据会错位。
// write: GMEM -> SMEM
int swizzled_col = row ^ col;
smem[row][swizzled_col] = gmem_in[row][col];
// read: SMEM -> GMEM
int swizzled_col = row ^ col;
gmem_out[col][row] = smem[row][swizzled_col];





Sudoku-like 映射视角
从本质上说,XOR 不是唯一选择。只要映射满足:
- 每行元素唯一
- 每列元素唯一
就可形成无冲突映射(类似 Sudoku 条件)。
选择 XOR 的原因是:计算简单、零额外查表开销。
Vectorized 与 Non-Vectorized 两类场景
- 对
GMEM <-> SMEM、SMEM -> RF这类16B访存,按 16B bank 粒度做 swizzling - 对
RF -> SMEM的4Bstore,需要先 swizzle 共享基址,再叠加线程内 offset



代码改动
Swizzling 函数
swizzling.cuh
#define BANKS_PER_VEC4_ACCESS 8
#define ELEMS_PER_BANK 8
__forceinline__ __device__ constexpr int get_swizzled_col(const int &row, const int &col) {
const int region_row = row % BANKS_PER_VEC4_ACCESS;
const int bank_col = col / ELEMS_PER_BANK;
const int bank_offset = col % ELEMS_PER_BANK;
return ((region_row ^ bank_col) * ELEMS_PER_BANK) + bank_offset;
}
三条路径统一接入 swizzling
GMEM <-> SMEM:列坐标先过get_swizzled_colSMEM -> RF(含 transpose 版本):ldmatrix地址采用 swizzled 列RF -> SMEM:按线程偏移写回时同样使用 swizzled 列
一句话原则:凡是读写 SMEM 的路径,都必须在地址层保持同一套 swizzled 映射。
性能结果
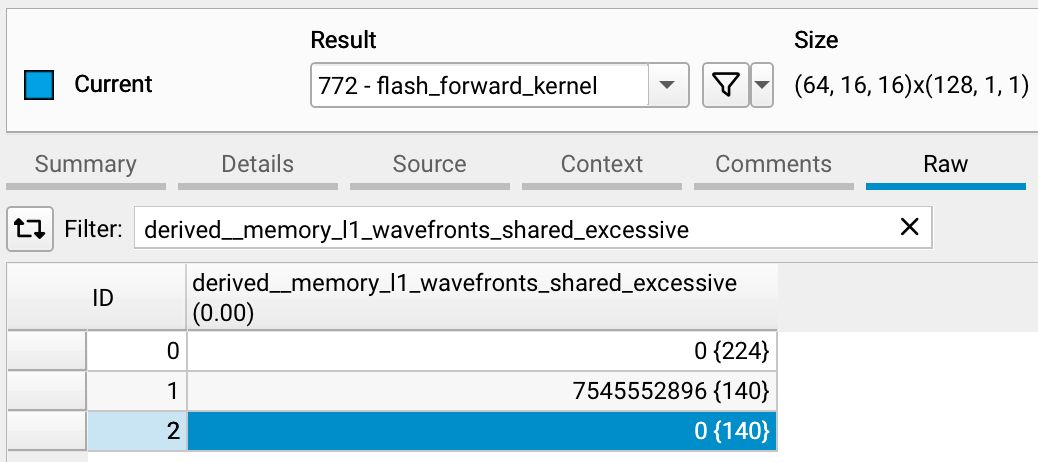
swizzling 后性能从 33.28 TFLOPS 提升到 66.12 TFLOPS,约 2x 提升。


Stall 对比(Kernel 1 -> Kernel 2)
| Stall | Kernel 1 | Kernel 2 | Delta (1->2) | Reference |
|---|---|---|---|---|
short_scoreboard |
56.37% | 1.49% | -54.88% | 0.52% |
mio_throttle |
11.66% | 0.74% | -10.92% | 1.37% |
long_scoreboard |
6.31% | 15.15% | +8.84% | 0.43% |
结论:
- SMEM 冲突基本被消除,短等待显著下降
- 但
long_scoreboard(等待 GMEM)占比上升,说明下一阶段优化重点将转向访存重叠与流水化
小结
Chapter4 的关键价值是:通过 swizzling 消除了 Kernel 1 的主要结构性瓶颈(SMEM bank conflicts),把性能直接拉升到接近参考实现。
下一章将继续引入 CUTLASS 风格的调优策略,重点提升计算与搬运的 overlap,进一步压缩与参考实现的差距。