简介
本附录聚焦 Ampere 微架构层面的执行约束,解释为什么同样的 kernel 在 A100 与 RTX 3090 上会表现出完全不同的瓶颈形态。
核心关注点:
- SM / sub-core 级执行单元如何竞争资源
- INT 与 FP32 pipeline 的发射与交错规则
mma与 FP32 吞吐比(16xvs2x)如何放大指令开销
原文参考:Appendix A - Ampere Microarchitecture。
Ampere 微架构概览
A100 的每个 SM 可视为由 4 个相同 sub-cores 组成,彼此可独立执行指令。
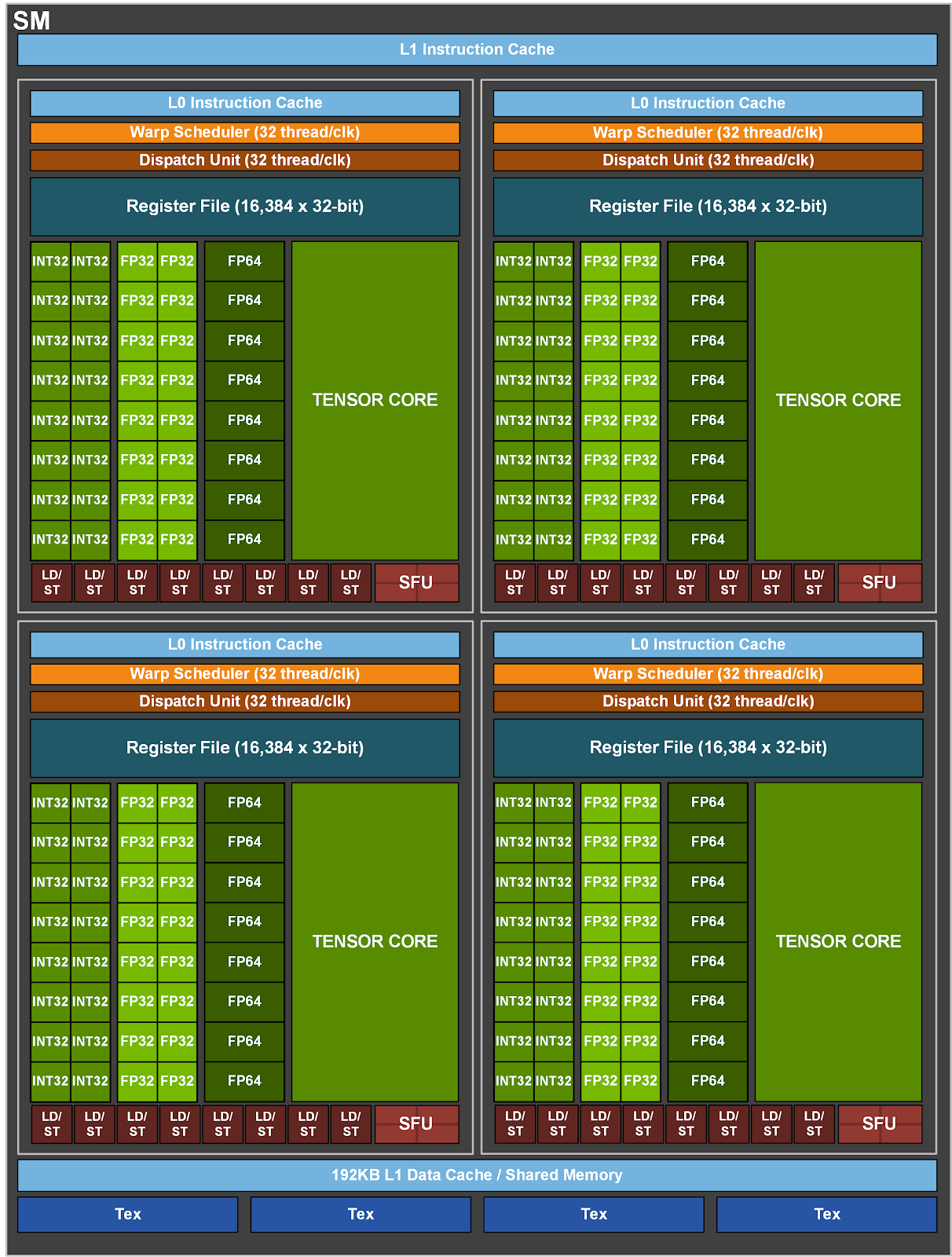
聚焦单个 A100 sub-core,可看到关键执行单元:
- INT units(逻辑与整数相关)
- FP32 units(浮点与部分整数乘法相关)
- SFUs(特殊函数,吞吐低、延迟高)
- Tensor Core(
mma相关)
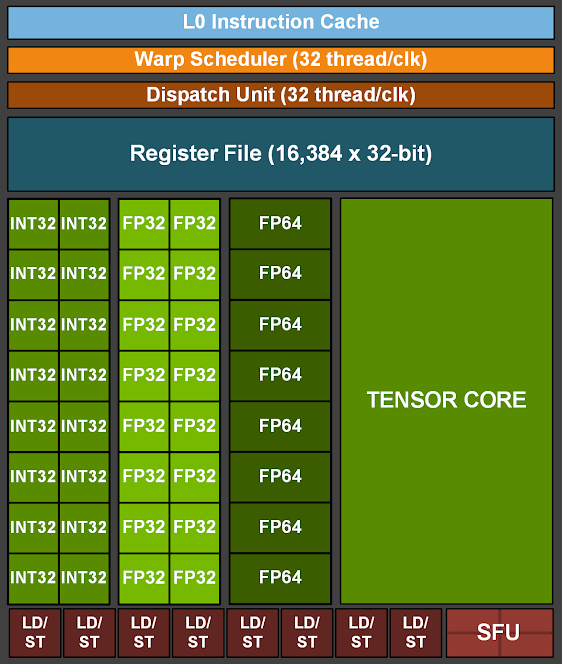
Ampere Scalar Pipelines
一个关键事实:每个 sub-core 每个 cycle 只能 dispatch 1 条指令。
而 FP32/INT 单元每 cycle 处理 16 lane,warp 有 32 threads,因此 FP32 或 INT 指令通常表现为 2 CPI 执行占用(这里是执行单元占用,不是调度器停顿)。
这导致一个重要调度机会:instruction interleaving。
例如:
- cycle 0:发 FP32(占用 FP32 pipeline)
- cycle 1:发 INT(占用 INT pipeline)
两者可在不同执行单元上并行推进,从而提高有效吞吐。
这也是为什么在 softmax 这类 FP-heavy 区段,合理穿插某些 INT 指令(如位移/拷贝)可能提升总体利用率。
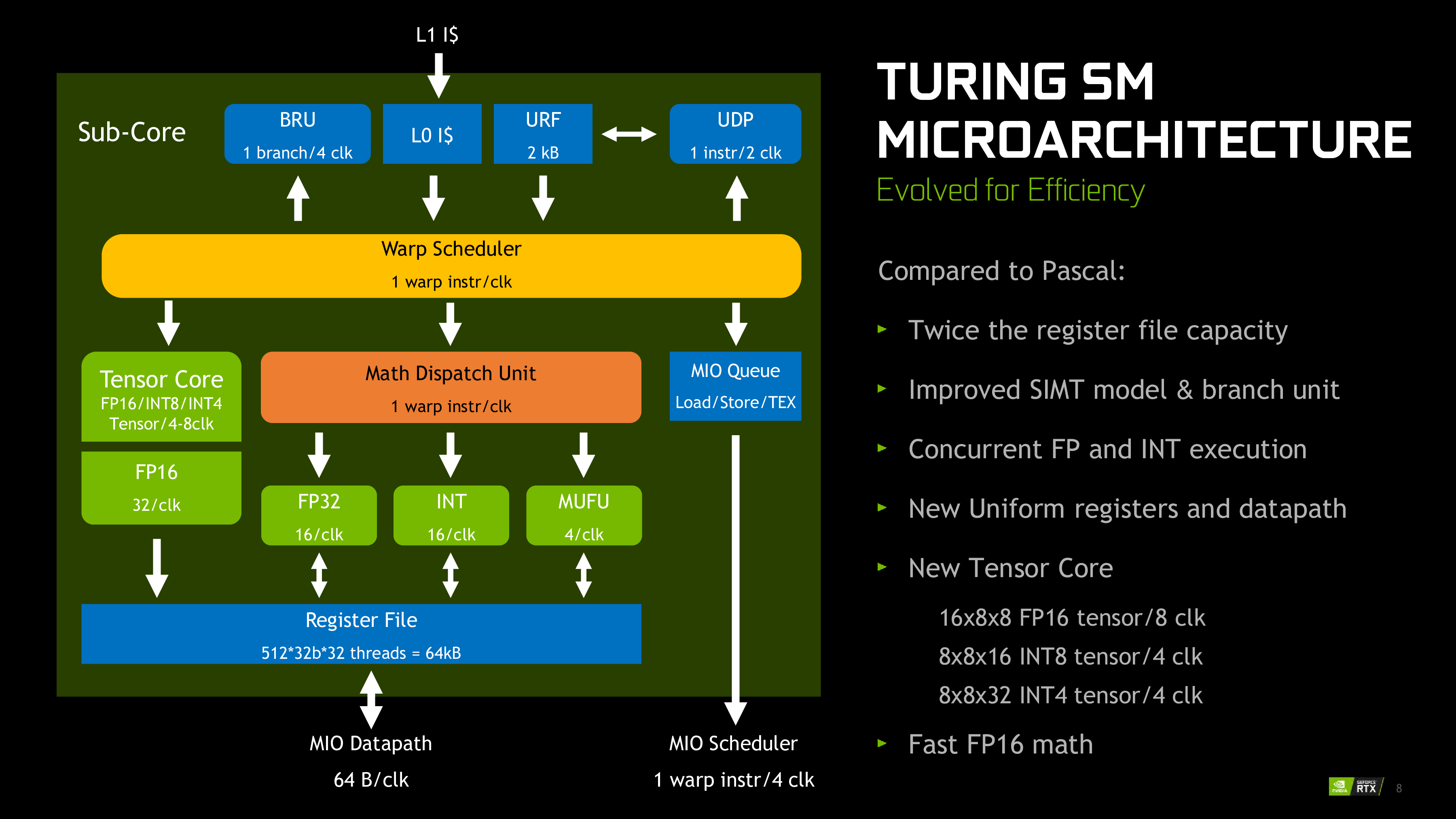
A100 vs RTX 3090:子核结构差异
A100(SM 8.0)与 RTX 3090(SM 8.6)在标量路径上的关键差别是:
- A100:INT 与 FP32 分工更“传统分离”
- RTX 3090:存在可处理 FP32/INT 的 hybrid 路径,带来更高 FP32 有效吞吐能力
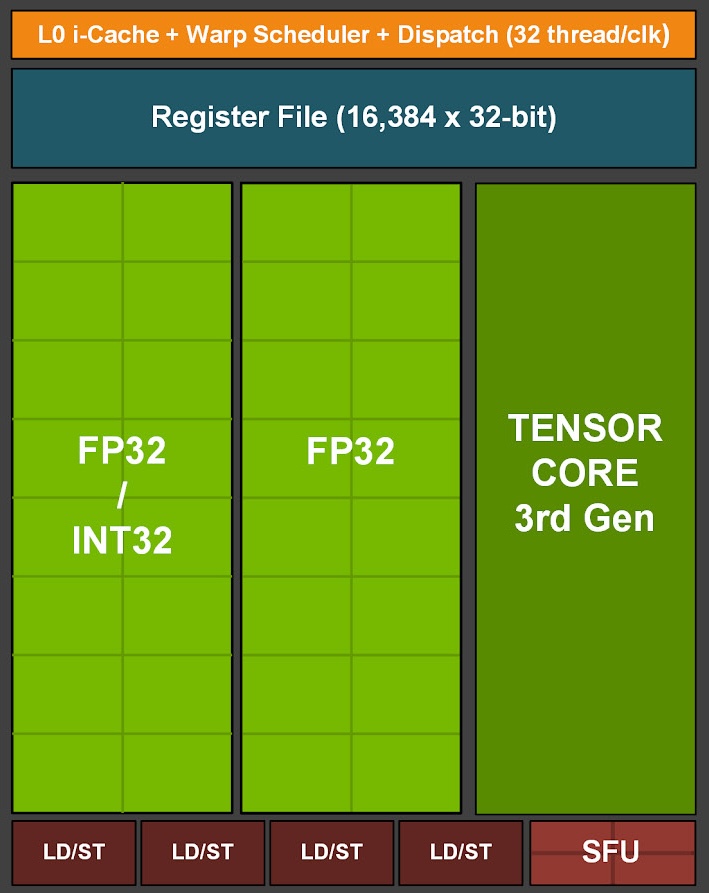
这正是后续“同 kernel 不同设备表现差异”的硬件基础之一。
吞吐比复核:为什么是 16x 与 2x
在 warp 粒度下:
- 一条
mma.m16n8k16:4096 FLOPs - 一条 FP32 FMA:
32 * 2 = 64 FLOPs
结合 issue rate(附录给定):
| Metric | A100 | RTX 3090 |
|---|---|---|
mma issue rate (clocks) |
8 | 32 |
| FP32 FMA issue rate (clocks) | 2 | 1 |
mma FLOPs/clock |
4096/8 = 512 |
4096/32 = 128 |
| FP32 FMA FLOPs/clock | 32 | 64 |
mma / FP32 ratio |
512/32 = 16x |
128/64 = 2x |
这解释了 Part 7 的关键现象:
A100 的 Tensor Core 吞吐远高于 FP32 路径,一旦 scalar 依赖链过长,就更容易出现“tensor starvation”。
Instruction Budget 直觉
在理想无依赖假设下,估算两次 mma 之间可“插入”的指令预算:
A100(mma 8 cycles)
- 非交错:约 4 条 INT/FP32
- 交错(INT+FP32):最多约 7 条
示意:
mma
FP32
INT
FP32
INT
FP32
INT
FP32
mma
...
RTX 3090(mma 32 cycles)
- 非交错:最多约 31 条 FP32 或 15 条 INT
- 交错:最多约 31 条
结论非常直接:RTX 3090 在 mma 间隔上给了更大“调度缓冲区”,对额外 scalar 指令更宽容;A100 对同类开销更敏感。
小结
Appendix A 的核心价值,是把“性能问题”还原到“微架构预算”:
- A100 的高 tensor 吞吐(相对 FP32)会放大 scalar 关键路径问题
- RTX 3090 的吞吐比更平衡,对同样指令开销容忍度更高
- 因此,优化重点不只是减少总指令,更要减少 阻塞关键指令的依赖链
这也为后续 SASS 级优化(减少 MOV/SHF/LOP3/IMAD.* 等非必要指令)提供了明确方向。